HADOOP
Hadoop is an Apache Software Foundation project that importantly provides two things:
-
A distributed filesystem called HDFS (Hadoop Distributed File System)
-
A framework and API for building and running MapReduce jobs
HDFS
HDFS is structured similarly to a regular Unix filesystem except that data storage is distributed across several machines. It is not intended as a replacement to a regular filesystem, but rather as a filesystem-like layer for large distributed systems to use. It has in built mechanisms to handle machine outages, and is optimized for throughput rather than latency.
There are two and a half types of machine in a HDFS cluster:
-
Datanode - where HDFS actually stores the data, there are usually quite a few of these.
-
Namenode - the ‘master’ machine. It controls all the meta data for the cluster. Eg - what blocks make up a file, and what datanodes those blocks are stored on.
-
Secondary Namenode - this is NOT a backup namenode, but is a separate service that keeps a copy of both the edit logs, and filesystem image, merging them periodically to keep the size reasonable.
- this is soon being deprecated in favor of the backup node and the checkpoint node, but the functionality remains similar (if not the same)

Data can be accessed using either the Java API, or the Hadoop command line client. Many operations are similar to their Unix counterparts.
Here are some simple examples:
list files in the root directory
<span style="color:rgb(0,0,255);"><code class="bash">hadoop fs -ls /
</code></span>
list files in my home directory
<span style="color:rgb(0,0,255);"><code class="bash">hadoop fs -ls ./
</code></span>
cat a file (decompressing if needed)
<span style="color:rgb(0,0,255);"><code class="bash">hadoop fs -text ./file.txt.gz
</code></span>
upload and retrieve a file
<span style="color:rgb(0,0,255);"><code class="bash">hadoop fs -put ./localfile.txt /home/vishnu/remotefile.txt
hadoop fs -get /home/vishnu/remotefile.txt ./local/file/path/file.txt
</code></span>
Note that HDFS is optimized differently than a regular file system. It is designed for non-realtime applications demanding high throughput instead of online applications demanding low latency. For example, files cannot be modified once written, and the latency of reads/writes is really bad by filesystem standards. On the flip side, throughput scales fairly linearly with the number of datanodes in a cluster, so it can handle workloads no single machine would ever be able to.
HDFS also has a bunch of unique features that make it ideal for distributed systems:
-
Failure tolerant - data can be duplicated across multiple datanodes to protect against machine failures. The industry standard seems to be a replication factor of 3 (everything is stored on three machines).
-
Scalability - data transfers happen directly with the datanodes so your read/write capacity scales fairly well with the number of datanodes
-
Space - need more disk space? Just add more datanodes and re-balance
-
Industry standard - Lots of other distributed applications build on top of HDFS (HBase, Map-Reduce)
-
HDFS Resources
For more information about the design of HDFS, you should read through apache documentation page. In particular the streaming and data access section has some really simple and informative diagrams on how data read/writes actually happen.
MapReduce
The second fundamental part of Hadoop is the MapReduce layer. This is made up of two sub components:
-
An API for writing MapReduce workflows in Java.
-
A set of services for managing the execution of these workflows.
The Map and Reduce APIs
The basic premise is this:
-
Map tasks perform a transformation.
-
Reduce tasks perform an aggregation.
In scala, a simplified version of a MapReduce job might look like this:
<span style="color:rgb(255,0,0);"><code class="scala"><span class="k">def</span> <span class="n">map</span><span class="o">(</span><span class="n">lineNumber</span><span class="k">:</span> <span class="kt">Long</span><span class="o">,</span> <span class="n">sentance</span><span class="k">:</span> <span class="kt">String</span><span class="o">)</span> <span class="k">=</span> <span class="o">{</span>
<span class="k">val</span> <span class="n">words</span> <span class="k">=</span> <span class="n">sentance</span><span class="o">.</span><span class="n">split</span><span class="o">()</span>
<span class="n">words</span><span class="o">.</span><span class="n">foreach</span><span class="o">{</span><span class="n">word</span> <span class="k">=></span>
<span class="n">output</span><span class="o">(</span><span class="n">word</span><span class="o">,</span> <span class="mi">1</span><span class="o">)</span>
<span class="o">}</span>
<span class="o">}</span>
<span class="k">def</span> <span class="n">reduce</span><span class="o">(</span><span class="n">word</span><span class="k">:</span> <span class="kt">String</span><span class="o">,</span> <span class="n">counts</span><span class="k">:</span> <span class="kt">Iterable</span><span class="o">[</span><span class="kt">Long</span><span class="o">])</span> <span class="k">=</span> <span class="o">{</span>
<span class="k">var</span> <span class="n">total</span> <span class="k">=</span> <span class="mi">0</span><span class="n">l</span>
<span class="n">counts</span><span class="o">.</span><span class="n">foreach</span><span class="o">{</span><span class="n">count</span> <span class="k">=></span>
<span class="n">total</span> <span class="o">+=</span> <span class="n">count</span>
<span class="o">}</span>
<span class="n">output</span><span class="o">(</span><span class="n">word</span><span class="o">,</span> <span class="n">total</span><span class="o">)</span>
<span class="o">}</span>
</code></span>
Notice that the output to a map and reduce task is always a KEY, VALUE pair. You always output exactly one key, and one value. The input to a reduce is KEY, ITERABLE[VALUE]. Reduce is called exactly once for each key output by the map phase. The ITERABLE[VALUE] is the set of all values output by the map phase for that key.
So if you had map tasks that output
<span style="color:rgb(255,0,0);"><code class="bash">map1: key: foo, value: 1
map2: key: foo, value: 32
</code></span>
Your reducer would receive:
<span style="color:rgb(255,0,0);"><code class="bash">key: foo, values: <span class="o">[</span>1, 32<span class="o">]</span>
</code></span>
Counter intuitively, one of the most important parts of a MapReduce job is what happens between map and reduce, there are 3 other stages; Partitioning, Sorting, and Grouping. In the default configuration, the goal of these intermediate steps is to ensure this behavior; that the values for each key are grouped together ready for the reduce() function. APIs are also provided if you want to tweak how these stages work (like if you want to perform a secondary sort).
Here’s a diagram of the full workflow to try and demonstrate how these pieces all fit together, but really at this stage it’s more important to understand how map and reduce interact rather than understanding all the specifics of how that is implemented.
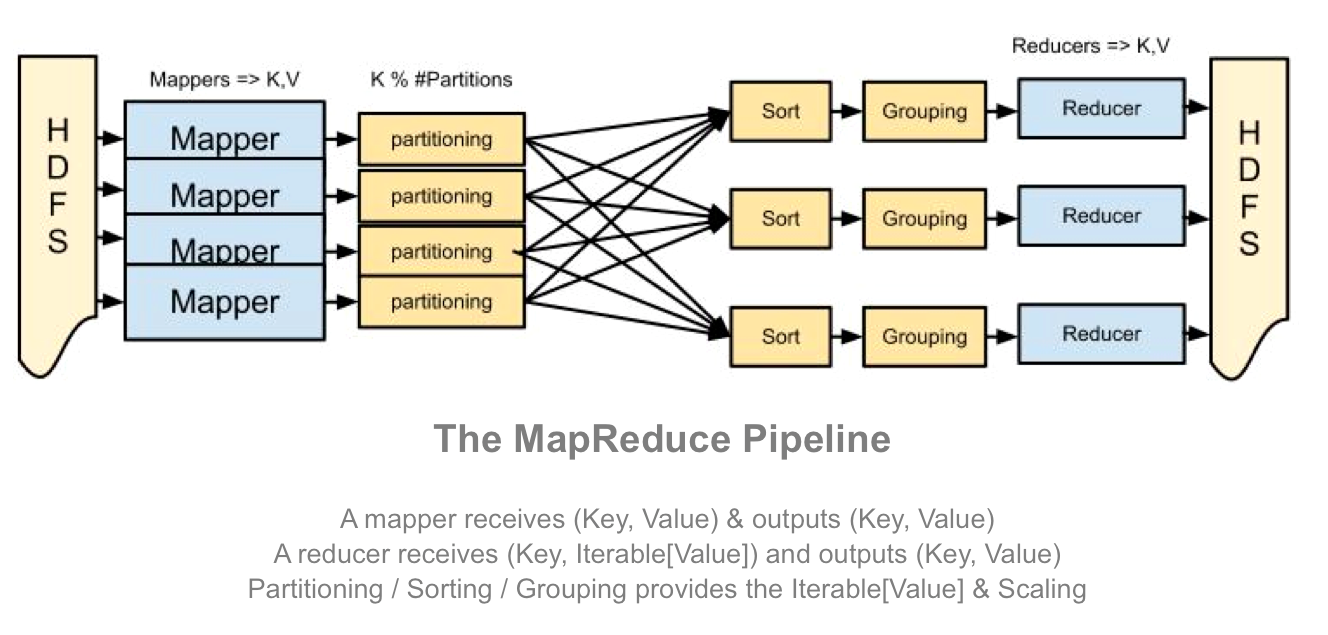
What’s really powerful about this API is that there is no dependency between any two of the same task. To do it’s job a map() task does not need to know about other map task, and similarly a single reduce() task has all the context it needs to aggregate for any particular key, it does not share any state with other reduce tasks.
Taken as a whole, this design means that the stages of the pipeline can be easily distributed to an arbitrary number of machines. Workflows requiring massive datasets can be easily distributed across hundreds of machines because there are no inherent dependencies between the tasks requiring them to be on the same machine.
MapReduce API Resources
If you want to learn more about MapReduce (generally, and within Hadoop) I recommend you read the Google MapReduce paper, the Apache MapReduce documentation, or maybe even the hadoop book. Performing a web search for MapReduce tutorials also offers a lot of useful information.
To make things more interesting, many projects have been built on top of the MapReduce API to ease the development of MapReduce workflows. For example Hive lets you write SQL to query data on HDFS instead of Java.
The Hadoop Services for Executing MapReduce Jobs
Hadoop MapReduce comes with two primary services for scheduling and running MapReduce jobs. They are the Job Tracker (JT) and the Task Tracker (TT). Broadly speaking the JT is the master and is in charge of allocating tasks to task trackers and scheduling these tasks globally. A TT is in charge of running the Map and Reduce tasks themselves.
When running, each TT registers itself with the JT and reports the number of ‘map’ and ‘reduce’ slots it has available, the JT keeps a central registry of these across all TTs and allocates them to jobs as required. When a task is completed, the TT re-registers that slot with the JT and the process repeats.
Many things can go wrong in a big distributed system, so these services have some clever tricks to ensure that your job finishes successfully:
-
Automatic retries - if a task fails, it is retried N times (usually 3) on different task trackers.
-
Data locality optimizations - if you co-locate a TT with a HDFS Datanode (which you should) it will take advantage of data locality to make reading the data faster
-
Blacklisting a bad TT - if the JT detects that a TT has too many failed tasks, it will blacklist it. No tasks will then be scheduled on this task tracker.
-
Speculative Execution - the JT can schedule the same task to run on several machines at the same time, just in case some machines are slower than others. When one version finishes, the others are killed.
Here’s a simple diagram of a typical deployment with TTs deployed alongside datanodes. 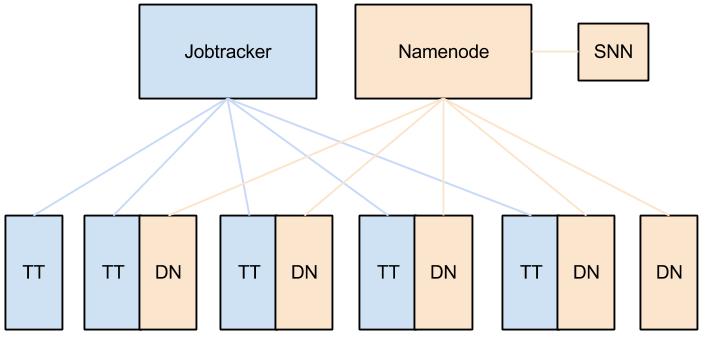
MapReduce Service Resources
For more reading on the JobTracker and TaskTracker check out Wikipedia or the Hadoop book. I find the apache documentation pretty confusing when just trying to understand these things at a high level, so again doing a web-search can be pretty useful.
Cluster
A cluster is a group of computers connected via a network. Similarly a Hadoop Cluster can also be a combination of a number of systems connected together which completes the picture of distributed computing. Hadoop uses a master slave architecture.
Components required in the cluster
NameNodes
Name node is the master server of the cluster. It doesnot store any file but knows where the blocks are stored in the child nodes and can give pointers and can re-assemble .Namenodes comes up with two features say Fsimage and the edit log.FSImage and edit log
Features
-
Highly memory intensive
-
Keeping it safe and isolated is necessary
-
Manages the file system namespaces
DataNodes
Child nodes are attached to the main node.
Features:
-
Data node has a configuration file to make itself available in the cluster .Again they stores data regarding storage capacity(Ex:5 out f 10 is available) of that particular data node.
-
Data nodes are independent ,since they are not pointing to any other data nodes.
-
Manages the storage attached to the node.
-
There will be multiple data nodes in a cluster.
Job Tracker
-
Schedules and assign task to the different datanodes.
-
Work Flow
-
Takes the request.
-
Assign the task.
-
Validate the requested work.
-
Checks whether all the data nodes are working properly.
-
If not, reschedule the tasks.
Task Tracker
Job Tracker and task tracker works in a master slave model. Every datanode has got a task tracker which actually performs the task which ever assigned to it by the Job tracker.
Secondary Name Node
Secondaryname node is not a redundant namenode but this actually provides the check pointing and housekeeping tasks periodically.
Types of Hadoop Installations
-
Standalone (local) mode: It is used to run Hadoop directly on your local machine. By default Hadoop is configured to run in this mode. It is used for debugging purpose.
-
**Pseudo-distributed mode: **It is used to stimulate multi node installation using a single node setup. We can use a single server instead of installing Hadoop in different servers.
-
**Fully distributed mode: **In this mode Hadoop is installed in all the servers which is a part of the cluster. One machine need to be designated as NameNode and another one as JobTracker. The rest acts as DataNode and TaskTracker.
How to make a Single node Hadoop Cluster
A Single node cluster is a cluster where all the Hadoop daemons run on a single machine. The development can be described as several steps.
Prerequisites
OS Requirements
Hadoop is meant to be deployed on Linux based platforms which includes OS like Mackintosh. Larger Hadoop production deployments are mostly on Cent OS, Red hat etc.
GNU/Linux is using as the development and production platform. Hadoop has been demonstrated on Linux clusters with more than 4000 nodes.
Win32 can be used as a development platform, but is not used as a production platform. For developing cluster in windows, we need Cygwin.
Since Ubuntu is a common Linux distribution and with interfaces similar to Windows, we’ll describe the details of Hadoop deployment on Ubuntu, it is better using the latest stable versions of OS.
This document deals with the development of cluster using Ubuntu Linux platform. Version is 12.04.1 LTS 64 bit.
Softwares Required
- Java JDK
The recommended and tested versions of java are listed below, you can choose any of the following
Jdk 1.6.0_20
Jdk 1.6.0_21
Jdk 1.6.0_24
Jdk 1.6.0_26
Jdk 1.6.0_28
Jdk 1.6.0_31
*Source Apache Software Foundation wiki. Test resukts announced by Cloudera,MapR,HortonWorks
-
SSH must be installed.
-
SSHD must be running.
This is used by the Hadoop scripts to manage remote Hadoop daemons.
- Download a latest stable version of Hadoop.
Here we are using Hadoop 1.0.3.
Now we are ready with a Linux machine and required softwares. So we can start the set up. Open the terminal and follow the steps described below
Step 1
Checking whether the OS is 64 bit or 32 bit
|
1 |
|
If it is showing a 64, then all the softwares(Java, ssh) must be of 64 bit. If it is showing 32, then use the softwares for 32 bit. This is very important.
Step 2
Installing Java.
For setting up hadoop, we need java. It is recommended to use sun java 1.6.
For checking whether the java is already installed or not
>$ java –version
This will show the details about java, if it is already installed.
If it is not there, we have to install.
Download a stable version of java as described above.
The downloaded file may be .bin file or .tar file
For installing a .bin file, go to the directory containing the binary file.
>$ sudo chmod u+x <filename>.bin
>$ ./<filename>.bin
If it is a tar ball
>$ sudo chmod u+x <filename>.tar
>$ sudo tar xzf <filename>.tar
Then set the JAVA_HOME in .bashrc file
Go to $HOME/.bashrc file
For editing .bashrc file
|
1 2 3 4 5 6 7 |
|
Now close the terminal, re-open again and check whether the java installation is correct.
|
1 |
|
This will show the details, if java is installed correct.
Now we are ready with java installed.
Step 3
Adding a user for using Hadoop
We have to create a separate user account for running Hadoop. This is recommended, because it isolates other softwares and other users on the same machine from hadoop installation.
|
1 2 3 |
|
Here we created a user “user” in a group “hadoop”.
Step 4
In the following steps, If you are not able to do sudo with user.
Then add user to sudoers group.
For that
|
1 |
|
Then add the following
|
1 |
|
This will give user the root privileges.
If you are not interested in giving root privileges, edit the line in the sudoers file as below
|
1 2 3 |
|
Step 5
Installing SSH server.
Hadoop requires SSH access to manage the nodes.
In case of multinode cluster, it is remote machines and local machine.
In single node cluster, SSH is needed to access the localhost for user user.
If ssh server is not installed, install it before going further.
Download the correct version (64bit or 32 bit) of open-ssh-server.
Here we are using 64 bit OS, So I downloaded open ssh server for 64 bit.
The download link is
https://www.ubuntuupdates.org/package/core/precise/main/base/openssh-server
The downloaded file may be a .deb file.
For installing a .deb file
|
1 2 3 |
|
This will install the .deb file.
Step 6
Configuring SSH
Now we have SSH up and running.
As the first step, we have to generate an SSH key for the user
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
Here it is needed to unlock the key without our interaction, so we are creating an RSA keypair with an empty password. This is done in the second line. If empty password is not given, we have to enter the password every time when Hadoop interacts with its nodes. This is not desirable, so we are giving empty password.
The next step is to enable SSH access to our local machine with the key created in the previous step.
|
1 2 3 |
|
The last step is to test SSH setup by connecting to our local machine with user. This step is necessary to save our local machine’s host key fingerprint to the useruser’sknown_hosts file.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
Step 7
Disabling IPv6
There is no use in enabling IPv6 on our Ubuntu Box, because we are not connected to any IPv6 network. So we can disable IPv6. The performance may vary.
For disabling IPv6 on Ubuntu , go to
|
1 |
|
Open the file sysctl.conf
|
1 |
|
Add the following lines to the end of this file
|
1 2 3 4 5 6 7 |
|
Reboot the machine to make the changes take effect
For checking whether IPv6 is enabled or not, we can use the following command.
|
1 |
|
If the value is ‘0’ , IPv6 is enabled.
If it is ‘1’ , IPv6 is disabled.
We need the value to be ‘1’.
The requirements for installing Hadoop is ready. So we can start hadoop installation.
Step 8
Hadoop Installation
Here I am using this version hadoop 1.0.3.
So we are using this tar ball.
We create a directory named ‘utilities’ in user.
Practically, you can choose any directory. It will be good if you are keeping a good and uniform directory structure while installation. It will be good and when you deal with multinode clusters.
|
1 2 3 4 5 |
|
Here the 2nd line will extract the tar ball.
The 3rd line will the permission(ownership)of hadoop-1.0.3 to user
Step 9
Setting HADOOP_HOME in $HOME/.bashrc
Add the following lines in the .bashrc file
|
1 2 3 4 5 6 7 |
|
Note: If you are editing this $HOME/.bashrc file, the user doing this only will get the benefit.
For making this affect globally to all users,
go to /etc/bash.bashrc file and do the same changes.
Thus JAVA_HOME and HADOOP_HOME will be available to all users.
Do the same procedure while setting java also.
Step 10
Configuring Hadoop
In hadoop, we can find three configuration files core-site.xml, mapred-site.xml, hdfs-site.xml.
If we open this files, the only thing we can see is an empty configuration tag
What actually happening behind the curtain is that, hadoop assumes default value to a lot of properties. If we want to override that, we can edit these configuration files.
The default values are available in three files
core-default.xml, mapred-default.xml, hdfs-default.xml
These are available in the locations
utilities/hadoop-1.0.3/src/core, utilities/hadoop-1.0.3/src/mapred,
utilities/hadoop-1.0.3/src/hdfs.
If we open these files, we can see all the default properties. Setting JAVA_HOME for hadoop directly
Open hadoop-env.sh file, you can see a JAVA_HOME with a path.
The location of hadoop-env.sh file is
hadoop-1.0.3/conf/hadoop-env.sh
Edit that JAVA_HOME and give the correct path in which java is installed.
|
1 |
|
|
1 2 3 |
|
Editting the Configuration files
All these files are present in the directory
hadoop-1.0.3/conf/
Here we are configuring the directory where the hadoop stores its data files, the network ports is listens to…etc
By default Hadoop stores its local file system and HDFS in hadoop.tmp.dir .
Here we are using the directory /app/hadoop/tmp for storing temparory directories.
For that create a directory and set the ownership and permissions to user
|
1 2 3 4 5 |
|
Here the first line will create the directory structure.
Second line will give the ownership of that directory to user
The third line will set the rwx permissions.
Setting the ownership and permission is very important, if you forget this, you will get into some exceptions while formatting the namenode.
1. Core-site.xml
Open the core-site.xml file, you can see empty configuration tags.
Add the following lines between the configuration tags.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
2. Mapred-site.xml
In the mapred-site.xml add the following between the configuration tags.
|
1 2 3 4 5 6 7 8 9 |
|
3. Hdfs-site.xml
In the hdfs-site.xml add the following between the configuration tags.
|
1 2 3 4 5 6 7 8 9 |
|
Here we are giving replication as 1, because we have only one machine.
We can increase this as the number of nodes increases.
Step 11
Formatting the Hadoop Distributed File System via NameNode.
The first step for starting our Hadoop installation is to format the distributed file system. This should be done before first use. Be careful that, do not format an already running cluster, because all the data will be lost.
user@ubuntu:~$ $HADOOP_HOME/bin/hadoop namenode –format
The output will look like this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
Step 12
Starting Our single-node Cluster
Here we have only one node. So all the hadoop daemons are running on a single machine.
So we can start all the daemons by running a shell script.
|
1 |
|
This willstartup all the hadoop daemonsNamenode, Datanode, Jobtracker and Tasktracker on our machine.
The output when we run this is shown below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
You can check the process running on the by using jps.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
Note: If jps is not working, you can use another linux command.
ps –ef | grepuser
You can check for each daemon also
ps –ef | grep
Step 13
StoppingOur single-node Cluster
For stopping all the daemons running in the machine
Run the command
|
1 |
|
The output will be like this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
Then check with jps
|
1 2 3 |
|
Step 14
Testing the set up
Now our installation part is complete
The next step is to test the installed set up.
Restart the hadoop cluster again by using start-all.sh
Checking with HDFS
- Make a directory in hdfs
|
1 2 3 4 |
|
If it is success list the created directory.
|
1 |
|
The output will be like this
|
1 |
|
If getting like this, the HDFS is working fine.
1. Copy a file from local linux file system
|
1 |
|
Check for the file in HDFS
|
1 2 3 |
|
If the output is like this, it is success.
Checking with a MapReduce job
Mapreduce jars for testing are available with the hadoop itself.
So we can use that jar. No need to import another.
For checking with mapreduce, we can run a wordcountmapreduce job.
Go to $HADOOP_HOME
Then run
|
1 |
|
This output will be like this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
|
The above shown are the programs that are contained inside that jar, we can choose any program.
Here we are going to run the wordcount process.
The input file using is the file that we already copied from local to HDFS.
Run the following commands for executing the wordcount
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
|
If the program executed successfully, the output will be in
user/user/trial/output/part-r-00000 file in hdfs
Check the output
|
1 |
|
If output is coming, then our installation is success with mapreduce.
Thus we checked our installation.
So our single node hadoop cluster is ready